

估计阅读时长: 2 分钟Docker镜像信息 GCModeller以R#语言的软件包的形式提供给客户使用,相应的R#语言的分析环境以Docker镜像的形式进行打包盒发布,Docker的基础镜像为ubuntu 22.04。 dotnet环境:.NET 6 R#语言安装位置:/usr/local/bin R#程序包安装列表: 索引 包名称 Github 1 GCModeller https://github.com/SMRUCC/GCModeller 2 REnv https://github.com/rsharp-lang/R-sharp […]
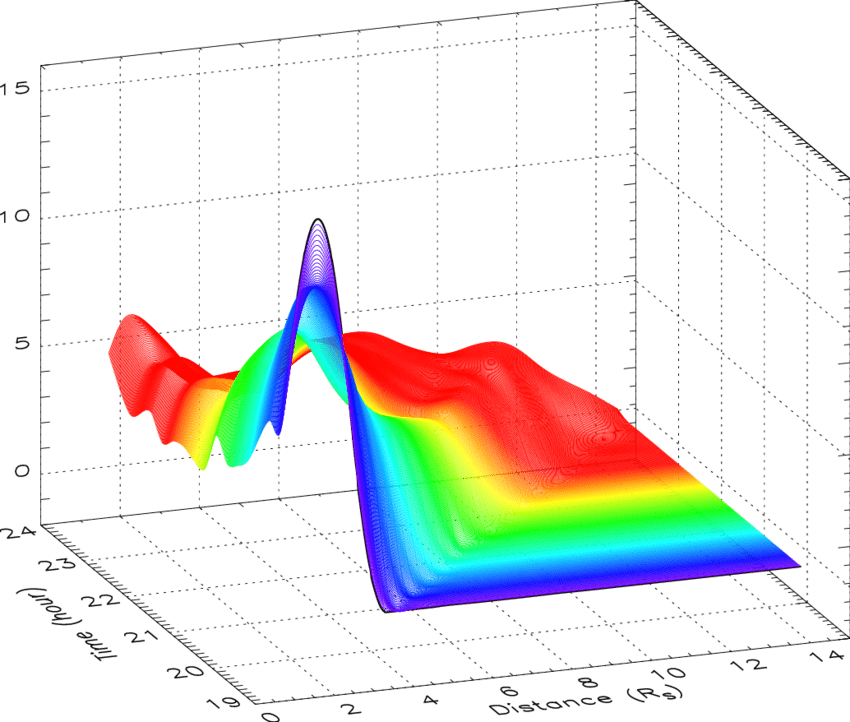
估计阅读时长: 7 分钟热图(Heat Map)是在二维空间中以颜色的形式显示一个现象的绝对量一种数据可视化技术。颜色的变化可能是通过色调或强度,给读者提供明显的视觉提示,说明现象是如何在空间上聚集或变化的。热图有两种完全不同的类别:聚集热图和空间热图。 在聚集热图中,幅度被排列成一个固定单元格大小的矩阵,其行和列是离散的现象和类别,行和列的排序是有意的,而且有些随意,目的是暗示聚集或描绘出通过统计分析发现的聚集。单元格的大小是任意的,但足够大,可以清晰可见。 相比之下,空间热图中某一量级的位置是由该量级在该空间中的位置所决定的,没有单元的概念,现象被认为是连续变化的。 Order by Date Name Attachments 2D-cubic-spline-interpolation-of-mass-profiles-from-1939-to-2354-UT-and-between-16 • 112 kB • 851 click […]
估计阅读时长: 7 分钟一般而言,进行全基因组的转录表达调控网络的建立,我们需要基于两个数据结果来完成: 目标基因的转录调控位点信息(Motif搜索结果,构成网络之中的节点) 转录调控位点相应的转录调控因子(Motif位点相关的转录调控因子,构成网络之中的边连接) Order by Date Name Attachments Xor • 271 kB • 707 click 2022年6月11日An […]
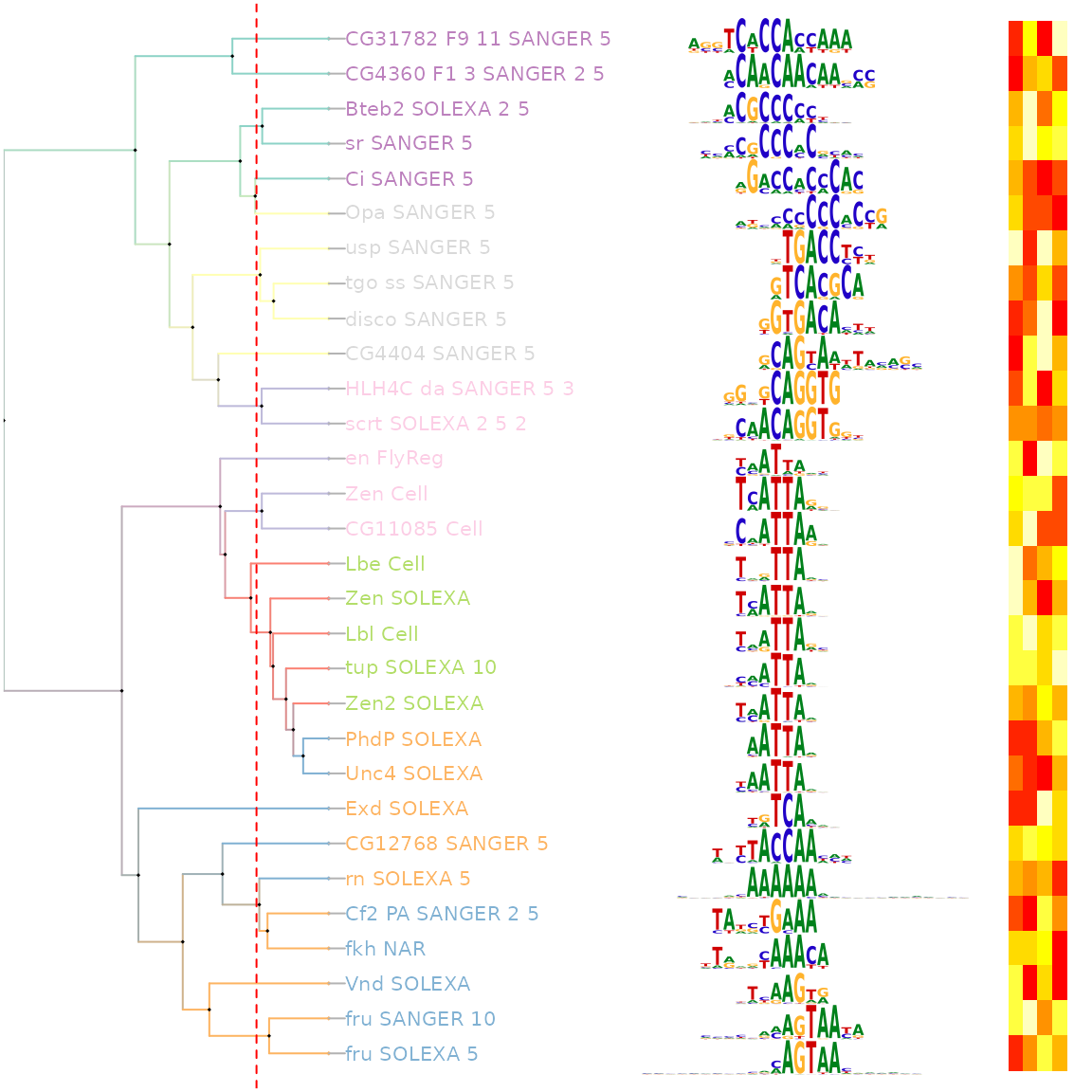
估计阅读时长: 12 分钟Motif是一段典型的序列或者一个结构。一般情况下是指构成任何一种特征序列的基本结构。通俗来讲,即是有特征的短序列,一般认为它是拥有生物学功能的保守序列,可能包含特异性的结合位点,或者是涉及某一个特定生物学过程的有共性的序列区段。比如蛋白质的序列特异性结合位点,如核酸酶和转录因子。 Order by Date Name Attachments Smith-Waterman-Algorithm-Example-Step3 • 8 kB • 706 click 2022年6月7日motifPilesHeatmap-1 • 227 […]
估计阅读时长: < 1 分钟Order by Date Name Attachments HEStainModelPreviews • 361 kB • 682 click 2022年6月3日13546516212177 • 152 kB […]
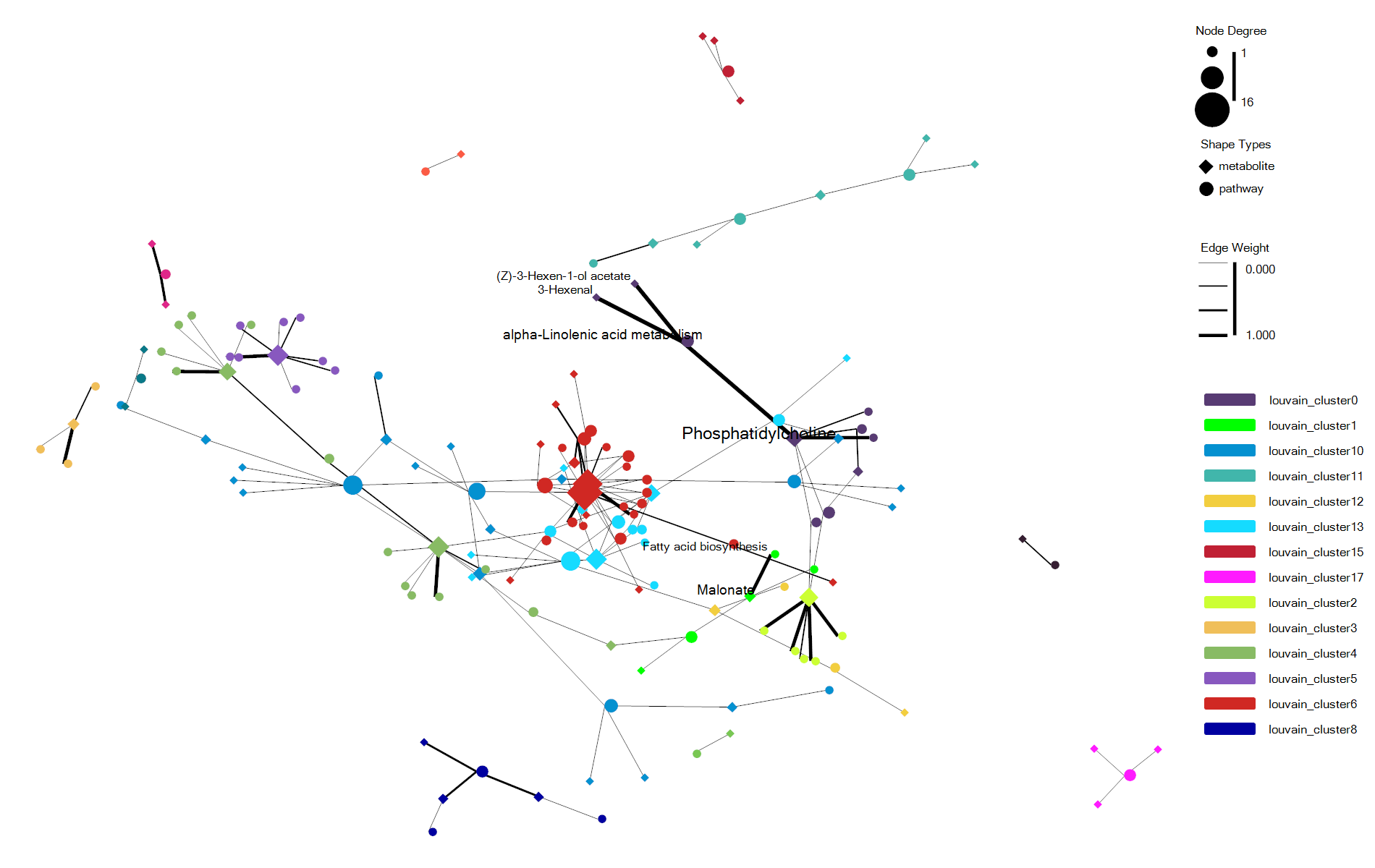
估计阅读时长: 7 分钟https://github.com/rsharp-lang/ggplot 在进行复杂关系的数据集进行可视化的时候,通过网络图的方式进行数据可视化可以让我们非常直观的借助于网络节点的聚集程度之类的布局信息了解到我们的复杂数据的关系结构信息。最近将R#语言之中的ggplot包进行网络可视化的代码库进行了一些更新。基于此功能更新工作,目前在ggplot程序包之中成功集成了ggraph程序包类似的网络可视化功能。在这里做了一些总结分享给大家。 Order by Date Name Attachments enrichNetwork_ggraph • 70 kB • 687 click 2022年6月1日enrichNetwork_ggraph2 • […]
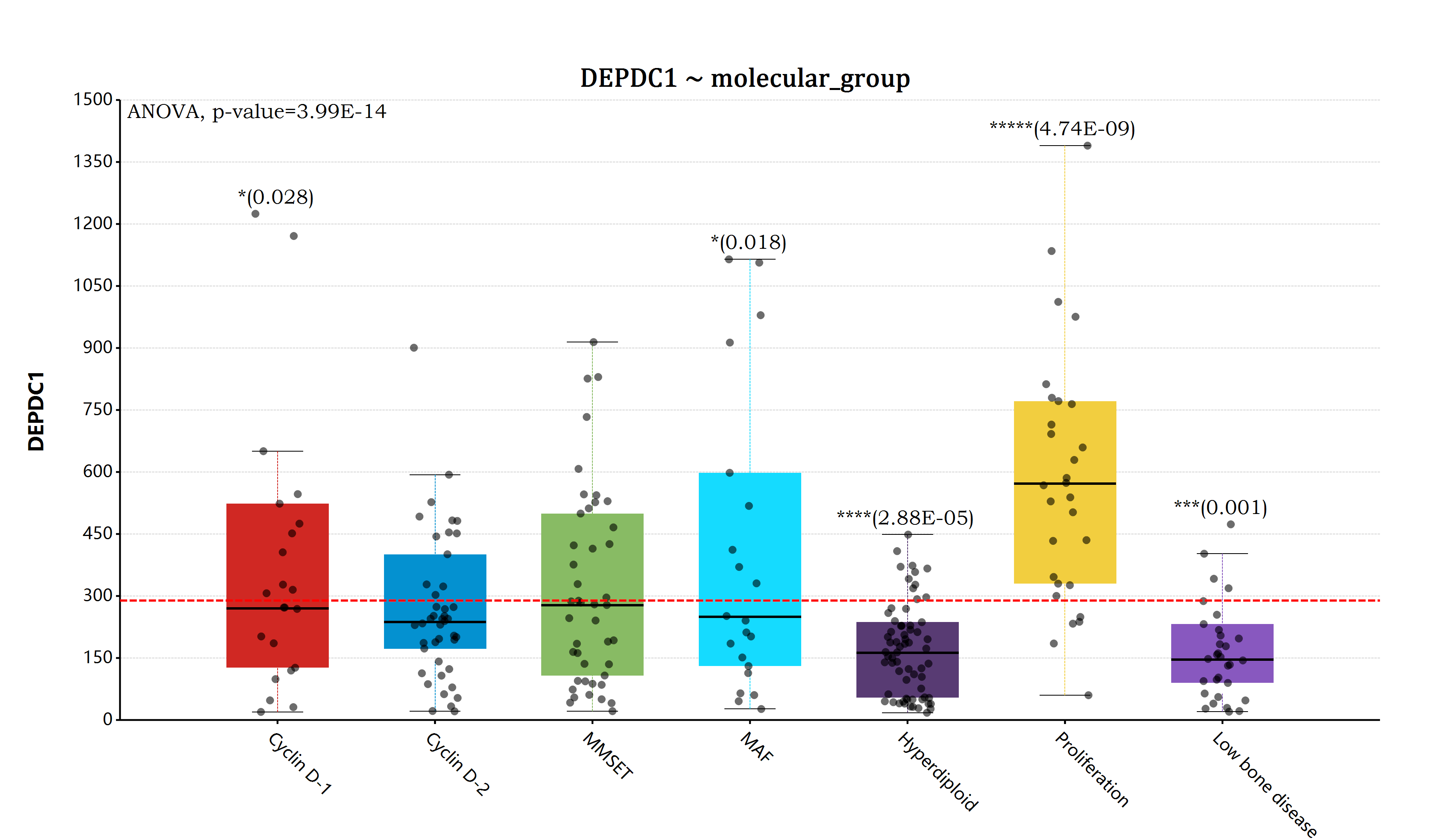
估计阅读时长: 14 分钟https://github.com/rsharp-lang/ggplot 在完成了前面所提到的ANOVA检验模块的代码开发编写工作之后,之前一直悬在我心里面的完善R#语言的ggplot统计作图功能的愿望现在终于实现了。在R#语言之中通过使用ggplot代码库进行相应的数据统计分析作图,目前已经变得和R语言之中的ggplot2程序包那样同样的简单和漂亮。 Order by Date Name Attachments myeloma_bar • 196 kB • 772 click 2022年5月29日myeloma_box • […]
估计阅读时长: 7 分钟F统计量是群体遗传学中由Sewall Wright提出的重要统计量,用于衡量遗传变异在群体中的分布情况。它提供了对群体遗传结构和遗传分化的定量描述。F统计量主要有三种类型:Fis、Fit和Fst,分别反映个体内的、总体的和群体间的遗传分化。F统计量在群体遗传学中通常指的是Fst(Fixation Index,固定指数),它是一个衡量群体间遗传差异的指标。Fst的值范围从0到1,其中0表示群体间没有差异,1表示群体间完全分离。在群体遗传学研究中,Fst常用于评估群体的遗传多样性、群体间的迁移率以及自然选择的压力等。 Order by Date Name Attachments 41598_2021_92984_Fig1_HTML • 2 MB • 747 click 2022年5月28日p1 […]
估计阅读时长: 14 分钟单细胞分析方法学习文献打卡记录: 【单细胞组学】PhenoGraph单细胞分型 【单细胞分析方法】VeTra:基于RNA速度的轨迹推断工具 【单细胞分析方法】单细胞图嵌入 Order by Date Name Attachments Cellular populations during motor neuron differentiation • […]
估计阅读时长: 7 分钟Assembles a manifold that is defined through a series of overlapping, locally-defined PCA subspaces. Non-mutual k-nearest-neighborhoods […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?