
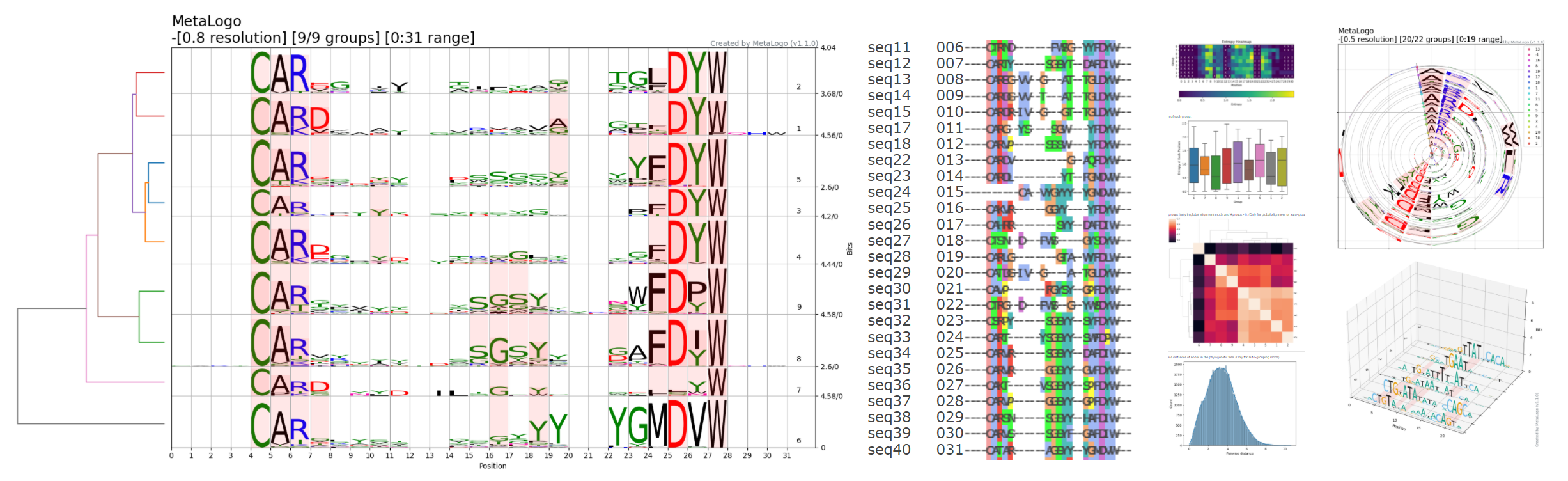
估计阅读时长: 23 分钟Sequence Logo 是一种可视化 DNA 或蛋白质序列保守性的图形表示方法。每个位置(列)上的字母堆叠高度代表该位点的信息含量(以 bits 为单位),而每个字母的高度则与其在该位点出现的频率成正比。高信息量的位置字母堆得高,低信息量的位置则矮甚至接近零。Sequence Logo的绘制遵循信息熵原理,我们可以很直观的通过某一个位置的总高低来了解该处位置的信息含量有多少,高信息量的位置,字母堆的高,一般会出现某一个字符特别高,表明该处非常保守。 位置权重矩阵(Position Weight Matrix, PWM)是描述基因组调控因子结合位点序列模式的核心模型。它通过统计在结合位点序列中每个位置上各核苷酸(或氨基酸)出现的频率,来量化该位置对不同碱基的偏好程度。PWM通常以矩阵形式表示,行对应核苷酸(A、C、G、T/U),列对应序列中的位置,矩阵元素即为该位置该核苷酸相对于背景的权重得分。这一模型简洁且易于计算,因此在转录因子结合位点(TFBS)等调控元件的识别和表征中被广泛采用。 Order by Date Name […]
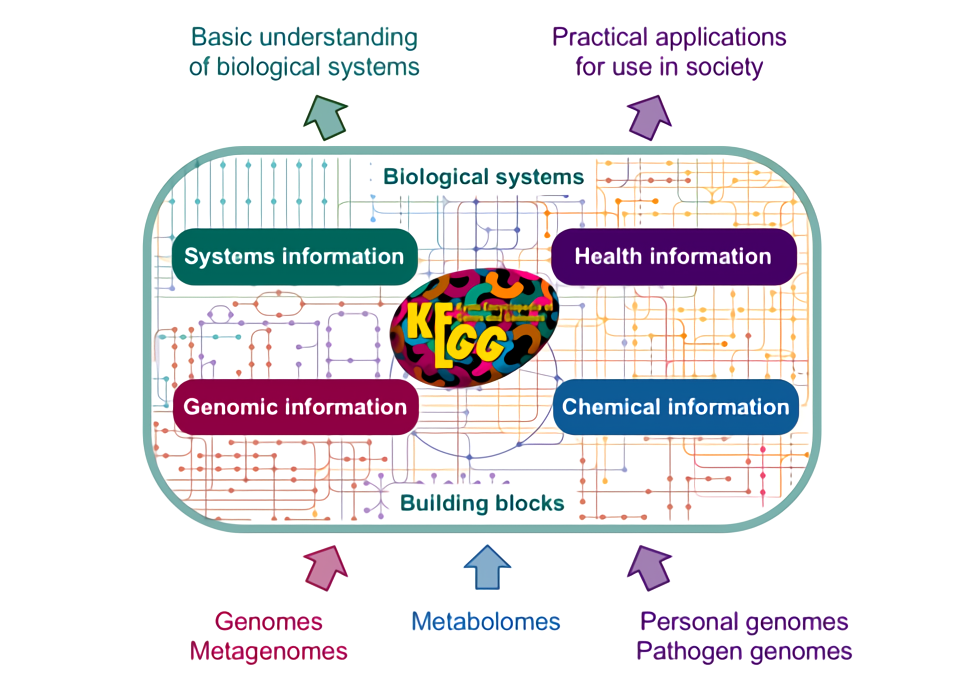
估计阅读时长: 34 分钟在前面写了一篇文章来介绍我们可以如何通过KEGG的BHR评分来注释直系同源。在KEGG数据库的同源注释算法中,BHR的核心思想是“双向最佳命中”。它比简单的单向BLAST搜索(例如,只看你的基因A在数据库里的最佳匹配是基因B)更为严格和可靠。在基因注释中,这种方法可以有效减少因基因家族扩张、结构域保守等原因导致的假阳性注释,从而更准确地识别直系同源基因,而直系同源基因通常具有相同的功能。在今天重新翻看了下KAAS的帮助文档之后,发现KAAS系统中更新了下面的Assignment score计算公式: We define a score for each ortholog group in order to assign the best […]

估计阅读时长: 5 分钟将复杂的生物学过程拆解为单元化学反应,是进行定量模拟的基石。转录是基因表达调控的关键环节,决定了细胞在特定时间、特定环境下合成哪些蛋白质,对生命活动至关重要。最近的工作中需要将原本非常粗糙的虚拟细胞转录事件模型拆解为更加细分化的多步骤生物化学过程,以适应针对细胞群落生长的建模计算。下面为我将原核生物的转录过程拆解为一系列可以用化学式表示的单元步骤的结果。 在介绍这些分步骤之前,我们会需要首先来定义一下模型中会用到的各种“化学物质”(分子和复合物): RNAP: RNA聚合酶全酶(包含核心酶和σ因子)。 DNA: 基因组DNA双链。 DNA_P: 包含启动子区域的DNA。 DNA_T: 包含终止子区域的DNA。 NTP: 核糖核苷三磷酸(ATP, UTP, GTP, CTP的统称)。 PPi: […]

估计阅读时长: 27 分钟宏基因组测序直接从环境样本获取所有生物的遗传物质,产生的海量短读序列(reads)需要被快速准确地分类到不同物种或功能类别。然而,宏基因组数据具有复杂性高、物种多样且未知序列多等特点,这给分类算法带来了巨大挑战。传统的序列比对方法虽然准确,但在面对庞大的参考数据库时计算开销巨大,难以满足实时分析的需求。因此,研究者开发了多种基于k-mer(长度为k的子序列)的快速分类方法,其中布隆过滤器(Bloom Filter)作为一种高效的概率数据结构,在针对测序reads做物种上的快速分类这项工作中起到了一些关键作用。 Attachments Capture • 112 kB • 269 click 2025年12月19日
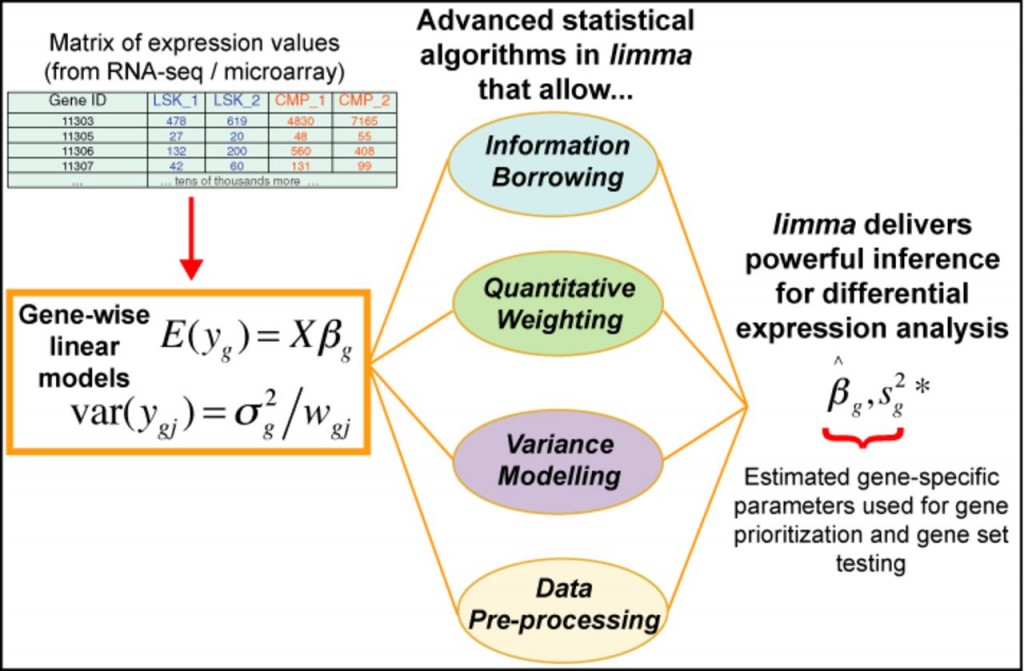
估计阅读时长: 22 分钟limma(Linear Models for Microarray Data)是一个基于R语言的Bioconductor包,最初用于微阵列数据的差异表达分析,现已扩展支持RNA-seq数据。其核心思想是利用线性模型(Linear Models)对基因表达数据进行建模,并结合经验贝叶斯(Empirical Bayes)方法在小样本情况下增强统计推断的稳健性。 Order by Date Name Attachments limma • 119 kB […]
估计阅读时长: 13 分钟LCA算法是现代宏基因组学分析的核心技术之一,主要用于解决序列比对结果的分类不确定性问题。例如,我们在处理宏基因组测序reads的物种来源分类注释工作的时候,经常会思考一个问题:在宏基因组分析中,一个测序read通常与多个参考序列产生比对结果,这些结果可能指向不同的分类单元。那这条reads最可能的物种分类来源位置是怎样的,怎样可以通过一个算法,基于一系列的物种匹配结果来推断出一个合适的物种来源,既避免过度分类,又保证分类的准确性。 Order by Date Name Attachments family-tree-animal-kingdom • 99 kB • 308 click 2025年12月2日LCA • 245 […]
估计阅读时长: 2 分钟宏基因组学(Metagenomics)通过直接测序环境样本中的全部DNA,从而避免了传统培养方法的局限,使我们能够研究不可培养微生物的多样性。然而,当样本来自宿主相关环境(如人类或小鼠的肠道、土壤等)时,测序数据中不可避免地包含大量宿主自身的DNA序列。这些宿主序列会占据测序读数,增加分析成本,并可能干扰对微生物群落组成的准确推断。因此,在宏基因组数据分析中,去除宿主序列(Host Sequence Removal)是至关重要的预处理步骤。去除宿主序列的算法多种多样,其中基于k-mer的方法因其高效和可扩展性而备受关注。 Attachments Metagenomics • 211 kB • 278 click 2025年11月29日
估计阅读时长: 6 分钟微生物全基因组代谢网络(Genome-scale metabolic model, GEM)模型的发展历史可追溯至20世纪90年代。1994年,Varma和Palsson在《Applied and Environmental Microbiology》期刊上发表了开创性论文,题为"Stoichiometric flux balance models quantitatively predict growth and metabolic by-product […]
估计阅读时长: 4 分钟基于UMAP工具进行简单的自动化组织分区操作 在这里我们假设已经可以正常的将空间代谢数据导入至MZKit工作站软件之中。假若需要借助于MZKit工作站软件进行切片组织样本的自动化分区操作,相关的功能可以在【MSI Analysis】菜单栏中寻找到。在这里我们打开【Show Map Layer】按钮,选择【UMAP and clustering】功能。 基于降维的组织自动化分区原理 因为降维操作一般是一种特征提取操作,所以经过降维之后,在高维度空间上无法显现的特征,在低维度会呈现出来。在高维度空间散落的相近的数据点,在经过特征提取之后,低维度上会产生相似的特征信息,相互聚集在一簇。这样子我们就可以在低维度空间上通过一些聚类算法讲这些特征进行聚类,最后将聚类特征结果标记到各个散点上的对应的原始成像空间上,我们就可以看见组织分区的结果了。 Abdelmoula, W.M., Lopez, B.GC., Randall, E.C. et […]

估计阅读时长: 24 分钟假若现在有两条Fasta序列放在你面前,现在需要你进行这两条Fasta序列的相似度计算分析。如果对于我而言,大学刚毕业刚入门生物信息学的时候,可能只能够想到通过blast比对的方式进行序列相似性计算分析。基于blast比对方式可以找到生物学意义上的序列相似性结果,但是计算的效率会比较低。假设现在让你使用这些序列进行机器学习建模分析,或者基于传统数学意义上的基于相似度的无监督聚类分析的时候,面对这些长度上长短不一的生物序列数据,可能会比较蒙圈,因为传统的数学分析方法都要求我们分析的目标至少应该是等长的向量数据。 Order by Date Name Attachments Fasta-A • 544 kB • 619 click 2023年6月29日visualize • 45 […]

[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 我们在基于前面所论述的《通过diamond软件进行blastp搜索》对大规模的基因组数据进行了代谢酶的EC number的注释以及按照文章《基因组功能注释(EC Number)的向量化嵌入》的方法,得到了一个比较大的基因组代谢酶TF-IDF嵌入丰度矩阵后,如果将这里所得到的嵌入结果矩阵中的基因组,基于Family层级的物种分类分组看作为单细胞转录数据中的细胞分群结果,能否基于单细胞数据分析方法来分析和可视化我的基因组功能嵌入的结果矩阵呢? […]
[…] 对于基于ec number来生成层级数据,我们直接使用《酶EC编号结构解析》文章末尾所展示的层级数据生成函数来实现。 […]
[…] 在前面的一篇《基因组功能注释(EC Number)的向量化嵌入》博客文章中,针对所注释得到的微生物基因组代谢信息,进行基于TF-IDF的向量化嵌入之后。为了可视化向量化嵌入的效果,通过UMAP进行降维,然后基于降维的结果进行散点图可视化。通过散点图可视化可以发现向量化的嵌入结果可以比较好的将不同物种分类来源的微生物基因组区分开来。 […]
😲啊?